Gengshan Yang | 杨庚山
I worked at World Labs from 2024 to early 2026, driving research and product iterations at the intersection of large 3D models and generative models. Prior to that, I was a research scientist at Meta.
I completed my PhD in Robotics at CMU, advised by Deva Ramanan. Here is my thesis. I've also interned at Google Research, FAIR, and Argo AI. I received the Qualcomm Innovation Fellowship (2021).
Google Scholar / Github / X / Email

Product
Code
A framework for 4D reconstruction from videos in pytorch.

Research
(Hover over images for animation)

Hao Zhang, Mohamed El Banani, Jen-Hao Cheng, Paul Zhang, Yi Hua, Ben Mildenhall, Christoph Lassner, Narendra Ahuja, Gengshan Yang
arXiv, 2026
World Tracing predicts a ray of camera-space 3D points, capturing both visible and occluded geometry via a diffusion transformer trained with pixel-space flow matching.

Jen-Hao Cheng, Yipeng Wang, Hao Zhang, Gengshan Yang, Jenq-Neng Hwang
arXiv, 2026
Flex4DHuman turns a single video or a few videos to dense multi-view syncronized videos via auto-regressive diffusion, without skeleton or depth inputs.

Ting-Hsuan Liao*, Haowen Liu*, Yiran Xu, Songwei Ge, Gengshan Yang*, Jia-Bin Huang*
SIGGRAPH Asia, 2025
PAD3R reconstructs freely moving instances with test-time-trained pose regressors.

Gengshan Yang, Andrea Bajcsy, Shunsuke Saito*, Angjoo Kanazawa*
ICLR, 2025
We learn interactive behavior models of an agent grounded in 3D from casual videos.

Jeff Tan, Donglai Xiang, Shubham Tulsiani, Deva Ramanan, Gengshan Yang
3DV, 2025 (Oral)
Dynamic 3D human with cloth & object interactions from a single video, enabled by a two-layer motion field that fuses 3D human prior and generic pixel priors (e.g., normal, flow).
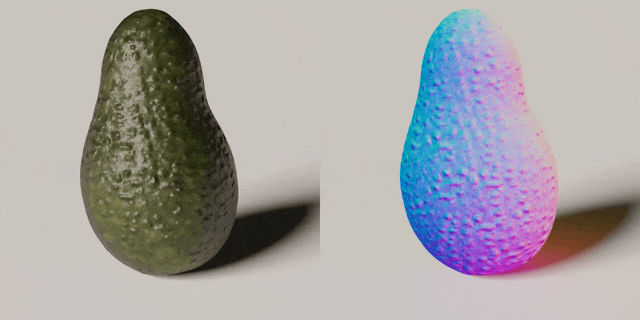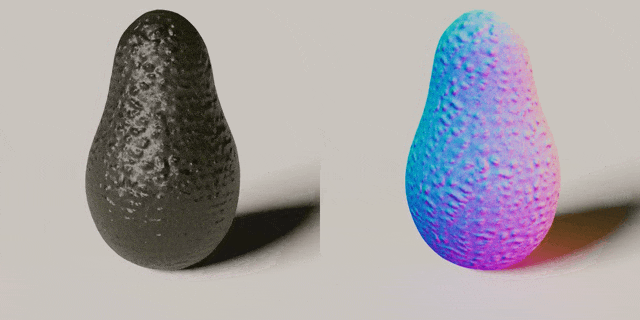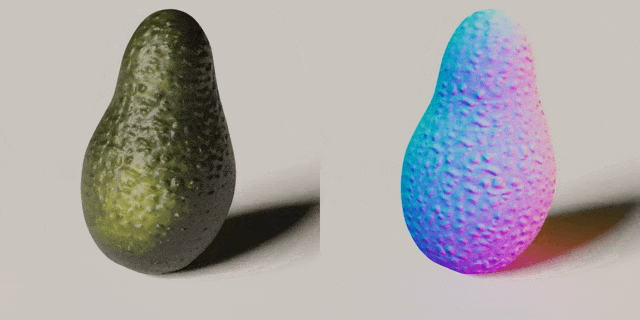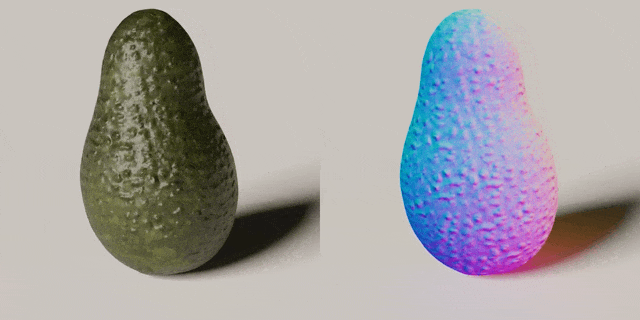
Ruihan Gao, Kangle Deng, Gengshan Yang, Wenzhen Yuan, Jun-Yan Zhu
NeurIPS, 2024
Using tactile sensing to enhance geometric details for 3D generation.

Nikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, Jonathon Luiten
CVPR, 2024
3D Gaussian Splatting for SLAM enables precise camera tracking and high-fidelity reconstruction using an RGBD camera.
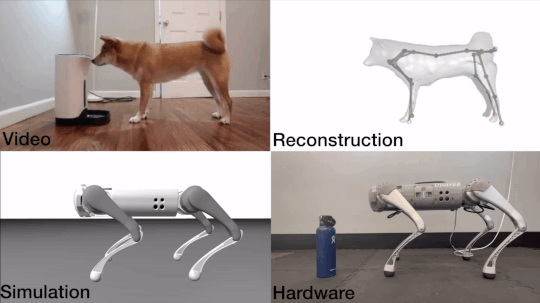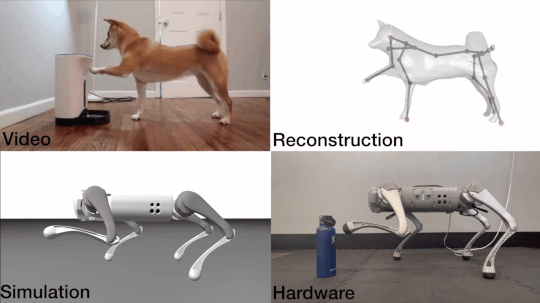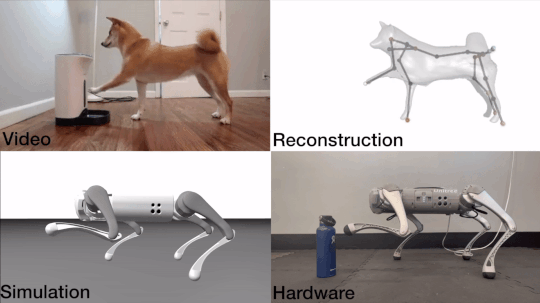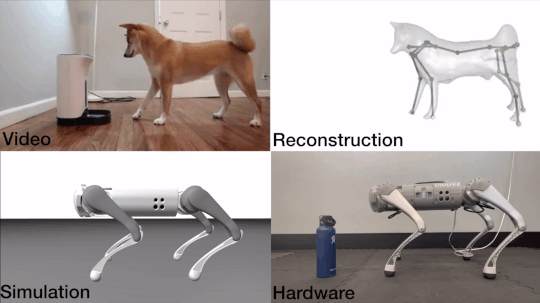
John Z. Zhang, Shuo Yang, Gengshan Yang, Arun Bishop, Swaminathan Gurumurthy, Deva Ramanan, Zachary Manchester
RA-L, 2023 / ICRA, 2024
An end-to-end motion transfer framework from monocular videos to legged robots.


Gengshan Yang, Shuo Yang, John Z. Zhang, Zachary Manchester, Deva Ramanan
ICCV, 2023 (Oral)
Given monocular videos, PPR builds 4D models of the object and the environment whose physical configurations satisfy dynamics and contact constraints.
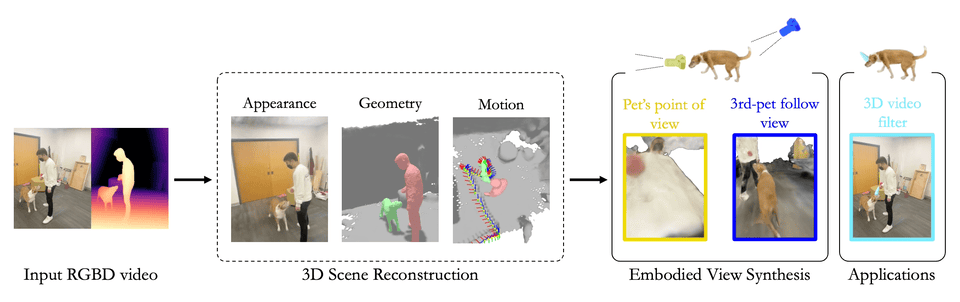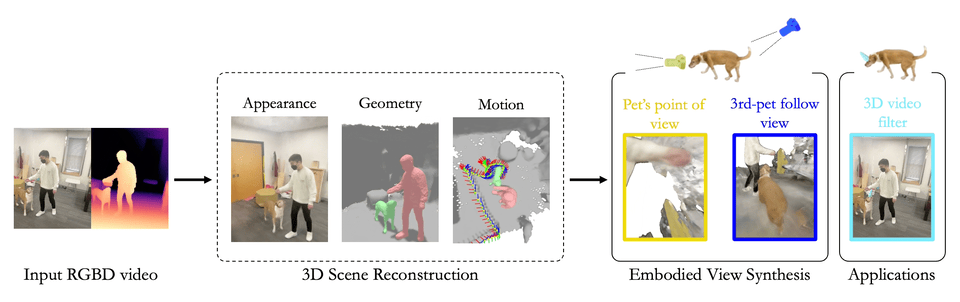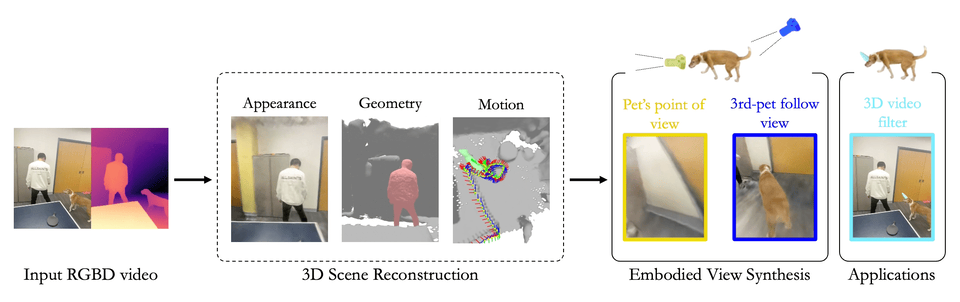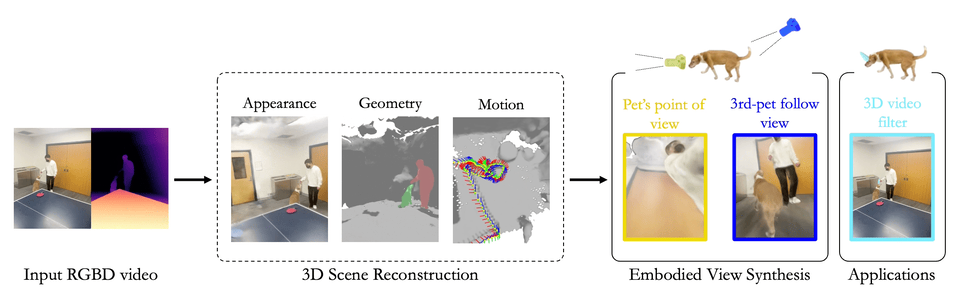
Chonghyuk Song, Gengshan Yang, Kangle Deng, Jun-Yan Zhu, Deva Ramanan
ICCV, 2023
Total-Recon explains an RGBD video with compositional 4D neural fields, which enables extreme view synthesis including embodied views, 3rd-person views, and bird's-eye views.

Gengshan Yang, Chaoyang Wang, N Dinesh Reddy, Deva Ramanan
CVPR, 2023
RAC learns category-level deformable 3D models from monocular videos. It disentangles morphology and motion and allows for motion retargeting.
Jeff Tan, Gengshan Yang, Deva Ramanan
CVPR, 2023
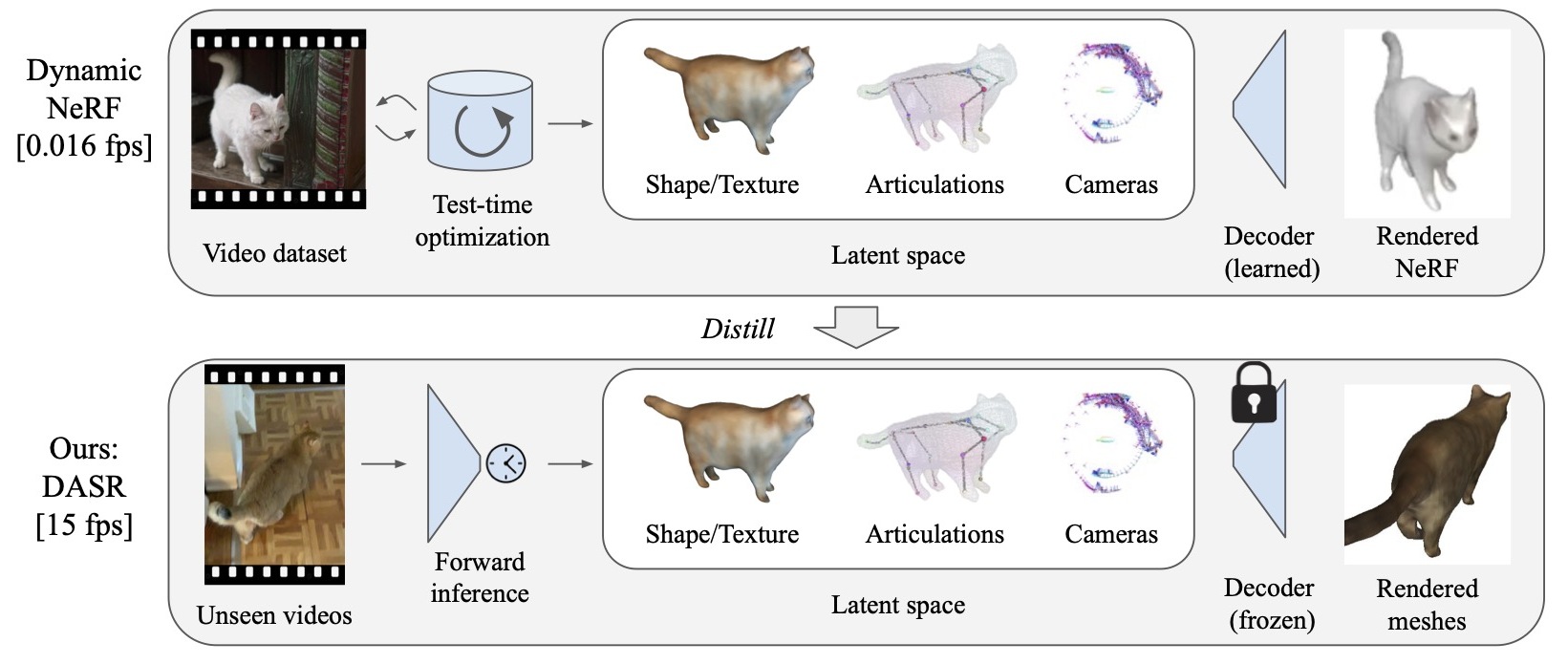
We distill offline-optimized dynamic NeRFs into efficient video shape, pose, and appearance predictors.
Kangle Deng, Gengshan Yang, Deva Ramanan, Jun-Yan Zhu
CVPR, 2023
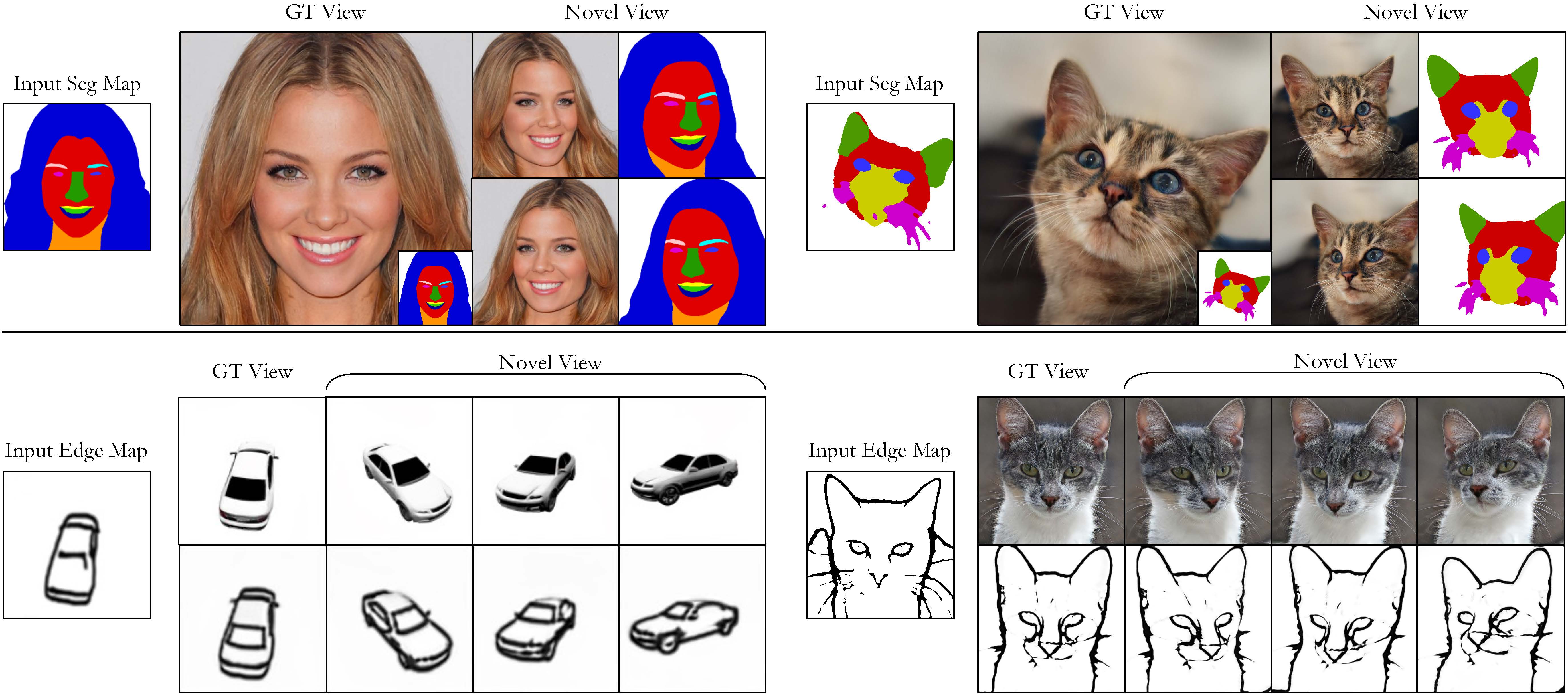
A 3D-aware conditional generative model for controllable image synthesis. Given a 2D label map, such as a segmentation or edge map, our model learns to synthesize images consistent from different viewpoints.

Gengshan Yang, Minh Vo, Natalia Neverova, Deva Ramanan, Andrea Vedaldi, Hanbyul Joo
CVPR, 2022 (Oral)
Given casual videos capturing a deformable object, BANMo reconstructs an animatable 3D model in a differentiable volume rendering framework.
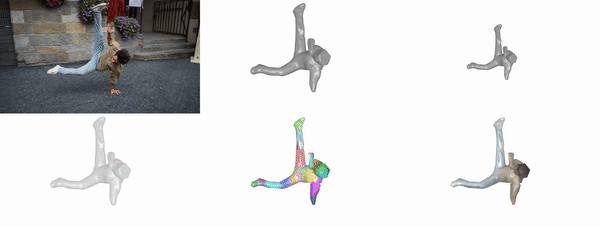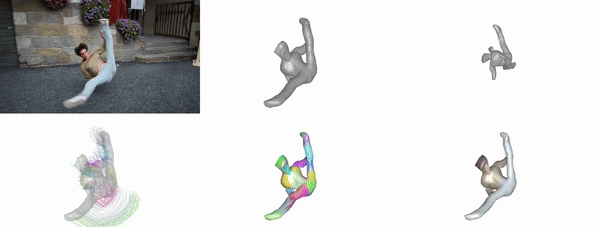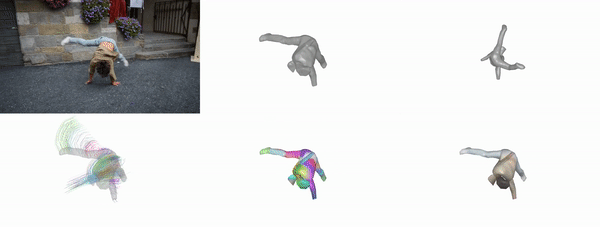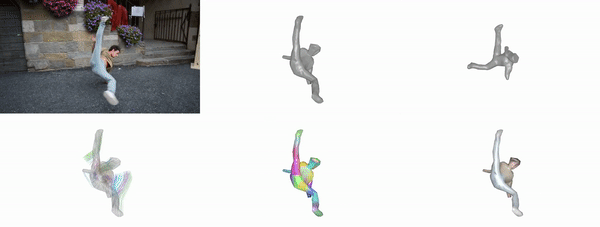
Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Ce Liu, Deva Ramanan
NeurIPS, 2021 (Spotlight)
Given a long video or multiple short videos, ViSER jointly optimizes articulated 3D shapes and a pixel-surface embedding to establish dense correspondences over video frames.

Jason Y. Zhang, Gengshan Yang, Shubham Tulsiani*, Deva Ramanan*
NeurIPS, 2021
Given several (8-16) unposed images of the same instance, NeRS optimizes for a textured 3D reconstruction along with the illumination parameters at test-time.

Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Huiwen Chang, Deva Ramanan, William T. Freeman, Ce Liu
CVPR, 2021
A template-free approach for articulated shape reconstruction from a single video by combining differentiable rendering and data-driven correspondence and segmentation priors.

Gengshan Yang, Deva Ramanan
CVPR, 2021
We analyze how to decompose two frames into a rigid background and multiple moving rigid bodies and propose a neural architecture to segment rigid motion groups given two frames.

Gengshan Yang, Deva Ramanan
CVPR, 2020 (Oral)
We describe a neural architecture to upgrade 2D optical flow to 3D scene flow using optical expansion, which reveals changes in depth of scene elements over frames, e.g., things moving closer will get bigger.
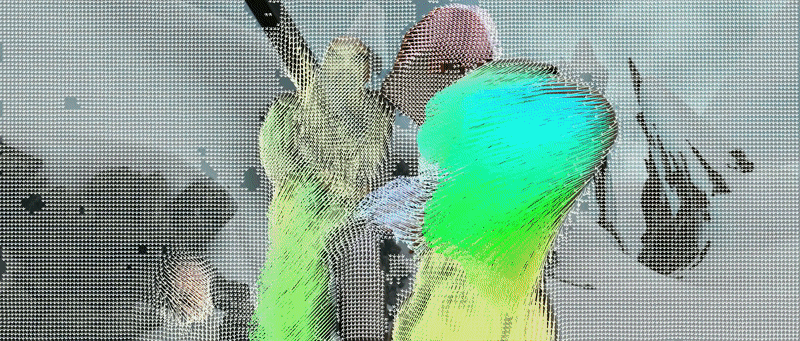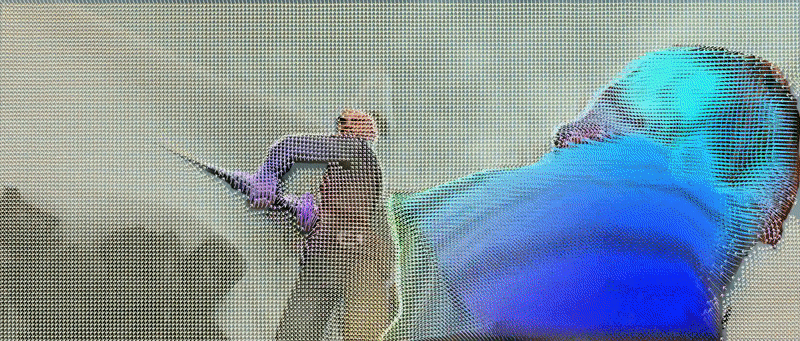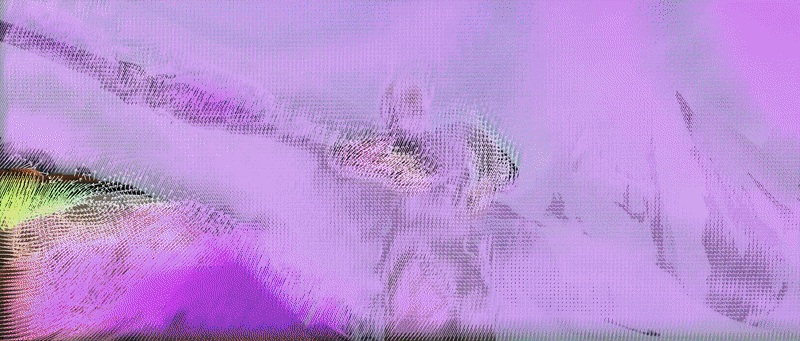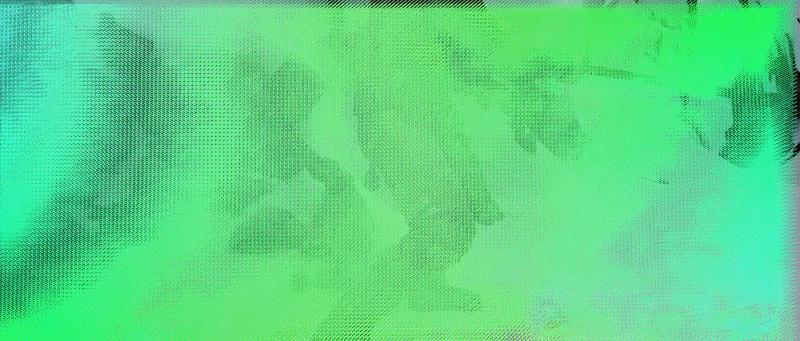
Gengshan Yang, Deva Ramanan
NeurIPS, 2019
We introduce several simple modifications to the optical flow volumetric layers that: 1) significantly reduces computation and parameters, 2) enables test-time adaptation of cost volume size, and 3) converges much faster.

Gengshan Yang, Joshua Manela, Michael Happold, Deva Ramanan
CVPR, 2019
To address the problem of real-time stereo matching on high-res imagery, an end-to-end framework that searches for correspondences incrementally over a coarse-to-fine hierarchy is proposed.
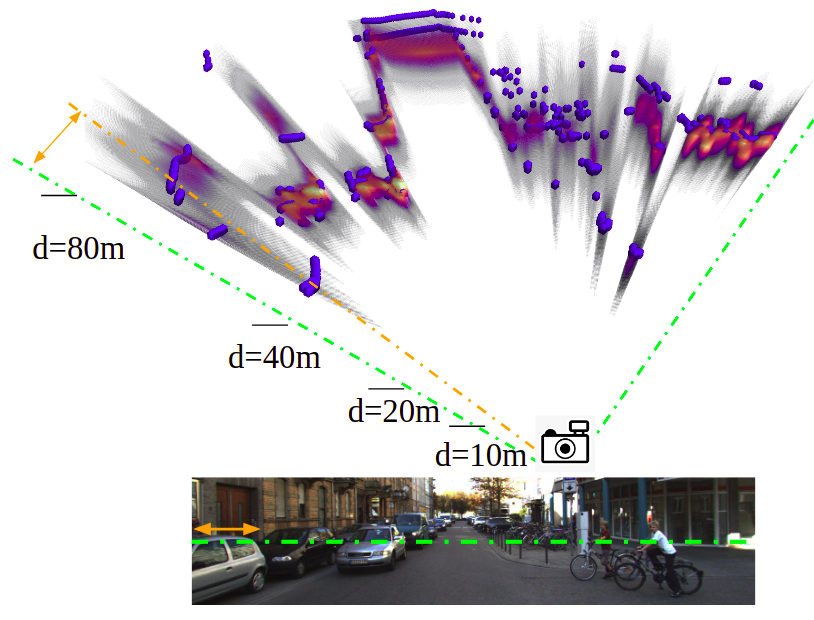
Gengshan Yang, Peiyun Hu, Deva Ramanan
IROS, 2019
We cast the continuous problem of depth regression as discrete binary classification, whose output is the occupancy probabilities on a 3D voxel grid. Such output reliably and efficiently captures multi-modal depth distributions in ambiguous cases.
Activities & Fun
The 4D Vision workshop at CVPR 25-26.
The 4th and 5th CV4Animals workshop at CVPR 24-25.
Carnegie Mellon Jazz Choir Fall 2022 performance.